

In 2013, I wrote a post for Moz titled “Transmedia Storytelling: Building Worlds For and With Fans.” The argument was simple but, at the time, unusual for the SEO community: brands that think like storytellers — building coherent narrative worlds across platforms rather than just repurposing content — win more than rankings. They win meaning.
That post applied Henry Jenkins‘ seven transmedia principles to search marketing. It talked about canonical consistency, fan co-creation, platform-native storytelling, and the brand as a storyworld people could inhabit.
Thirteen years later, every word of that thesis is more relevant than I could have imagined, but the audience has changed. The most important consumers of our brand narrative are no longer just humans scrolling through search results. They are Large Language Models reconstructing our brand story from fragments scattered across the web and then presenting that reconstruction to your customers as fact.
This is not a metaphorical shift but a structural one. And if we don’t build our brand as a transmedia storyworld that machines can reliably parse, we will lose control of how our brand is understood; not someday, but now.
The problem: our brand narrative is being written without us
Here’s the uncomfortable reality senior SEOs, Heads of Growth, and even CMOs must confront: AI search engines don’t read our websites and relay our messages. They synthesize a brand narrative from dozens of sources — our site, Reddit threads, YouTube transcripts, Quora answers, review sites, news articles, Wikipedia, structured data — and present a composite story to the user.
Each AI surface does this differently. And “differently” is an understatement.
- Google AI Overviews carry between 12 and 14 inline citations per response, but while brands are now cited more (especially for products and services), 0-click has already risen to represent the 58%/60% of all searches. Moreover, a vast majority of AIOs now links back to Google-owned properties (YouTube, Google Maps, or internal search results), which has reduced the “share of voice” for independent brands (source).
- Reddit, YouTube, and LinkedIn dominate the sourcing. Google is deliberately minimizing commercial content in this layer, as we can read in this article on Search Engine Land.
- Google AI Mode, despite being the same company’s product, behaves like a different medium entirely. Brands appear in 90% of AI Mode responses and surface 3.8x more unique brands than AI Overviews. The citation overlap between the two for identical queries is just 13.7%. In other words, they agree on what to say but disagree on who to cite.
- ChatGPT Search, with roughly 2 billion daily queries and over 60% market share among AI platforms, rewards broad distribution and consistency. Brands present on four or more platforms are 2.8x more likely to appear in ChatGPT responses. Wikipedia dominates at 47.9% of citations for informational queries. Reddit and Quora mentions yield 4x higher citation likelihood. ChatGPT trusts what the internet agrees on.
- Perplexity is the most community-driven surface: Reddit accounts for 6.6% of total citations, and niche sources make up 24% of citations for subjective queries; the highest of any platform. It surfaces content within 24 hours of publication.
- Gemini has the highest brand-owned citation rate at 52.15%, trusting what the brand says about itself.
- And Apple is building “World Knowledge Answers“, an AI-powered answer engine for Siri expected in 2026 that will generate multimodal summaries, adding yet another surface where your brand narrative will be constructed without your direct participation.
The result? A single brand is simultaneously described in five or six different ways by five or six different AI systems, each pulling from a different subset of sources, each weighting different signals, each constructing a different version of “your story.”
Myriam Jessier calls this “AI Brand Drift” and has mapped four layers of brand existence in this environment: the Known Brand (your official messaging), the Latent Brand (UGC, forums, cultural signals), the Shadow Brand (old documents, semi-public files, outdated content), and the AI-Narrated Brand, or how AI systems actually summarize and present you.
Ignore any layer, and AI systems will construct your brand narrative without your input.
Why transmedia storytelling is the right framework

 Riot Games executed what many call the “Gold Standard” of modern transmedia by moving from a game (where the story was secondary) to a prestige Netflix series.
Riot Games executed what many call the “Gold Standard” of modern transmedia by moving from a game (where the story was secondary) to a prestige Netflix series.
Riot didn’t just drop a show; they launched “RiotX Arcane,” a month-long event where the story’s events, Fortnite, and even PUBG.
They used “environmental storytelling” within the game maps to tease show plot points, creating a feedback loop where the show explained the game’s lore and the game rewarded the show’s viewers.
If this fragmentation sounds familiar, it should. It is the exact problem transmedia storytelling was designed to solve, albeit not for brands and search engines, but for entertainment franchises and audiences.
Henry Jenkins defined transmedia storytelling in Convergence Culture (2006) and refined it in his 2009 “Revenge of the Origami Unicorn” blog series as a process where “integral elements of a fiction get dispersed systematically across multiple delivery channels for the purpose of creating a unified and coordinated entertainment experience.“
Each medium makes its own unique contribution. Each entry point must be self-contained enough to enable autonomous consumption. Each piece enriches the whole.
The parallels to AI search are not metaphorical but structural.
Ed Finn, writing on Jenkins’ own blog in April 2024 as part of the release of Imagining Transmedia (MIT Press, 2024), made the connection explicit: the large language models powering ChatGPT and similar tools are deeply rooted in transmedia principles, where meaning and connections are drawn from photos, forum posts, math problems, and any medium. Build a thick enough web of connections and context, and you create a system that generates plausible new connective tissue on the fly.
That “plausible new connective tissue” is what an LLM produces when a user asks “tell me about [your brand].” The question is whether your brand has built a coherent storyworld that constrains what “plausible” means or whether you’ve left it to chance.
Jenkins’ seven principles, updated for AI search

 Barbie owned the entire concept of the color “Pink.”
Barbie owned the entire concept of the color “Pink.”
The campaign wasn’t just trailers. It was a massive world-building effort, including a real-life Airbnb Malibu Dreamhouse, a “Barbie Selfie Generator” (AI tool), and over 165 brand partnerships (from Progressive insurance to Xbox).
The marketing blurred the line between our world and “Barbie Land.” By the time the movie was released, the audience felt they were already residents of the world. It turned “wearing pink to the theater” into a narrative act of participation.
In the 2013 Moz post, I mapped Jenkins’ seven transmedia principles to brand marketing and SEO. Let me update each one on the reality of AI-mediated search.
Spreadability vs. Drillability

Jenkins framed this as a tension between breadth of sharing (spreadability, aka content that travels across platforms) and depth of engagement (drillability, aka content that rewards deep exploration).
In AI search, this tension becomes existential.
Spreadability now means being visible not just across social platforms but across AI surfaces: Google AI Overviews, AI Mode, ChatGPT, Perplexity, Gemini, Copilot.
AI systems build brand representations by triangulating across sources. If you exist in only one place, you don’t exist for the model.
But spreadability without drillability is noise.
AI Mode uses “query fan-out”; in plain words, breaking complex prompts into sub-queries executed simultaneously. If your content is wide but thin, the fan-out finds nothing worth citing.
Drillability means producing topical depth that AI can mine: comprehensive guides, detailed analyses, data-rich resources that become the authoritative substrate AI relies on for a specific topic cluster.
The operational question: are you spread across AI surfaces AND deep enough to be cited when the model drills?
Continuity vs. Multiplicity

Continuity, in Jenkins’ framework, means maintaining canonical coherence; the storyworld’s facts remain consistent across all extensions. Multiplicity means allowing alternative versions, retellings, and “what if” scenarios that enrich the universe without breaking it.
For AI search, continuity is the single most important architectural principle.
Jason Barnard calls it the “Infinite Self-Confirming Loop of Corroboration“, which means that the same facts about your brand are repeated consistently across authoritative sources until AI systems have no choice but to treat them as settled truth.
Your founding year, your product categories, your geographic presence, your key personnel, your value proposition, all this information must be identical everywhere. Not similar. Identical.
Multiplicity, paradoxically, is what the AI surfaces provide, whether you want it or not.
Gemini trusts your website. ChatGPT trusts Reddit consensus. Perplexity trusts community voices. Each is a “retelling” of your brand from a different perspective. The strategic question is not how to prevent multiplicity — you can’t — but how to ensure that every retelling is grounded in the same canonical facts. In transmedia terms: let the adaptations vary but protect the canon.
Rand Fishkin’s SparkToro study (late 2025, 600 volunteers, nearly 3,000 prompt runs) quantified the multiplicity problem: fewer than 1 in 100 runs produced the same brand list for identical queries. Fewer than 1 in 1,000 produced the same list in the same order. AI recommendations are inherently stochastic. But Fishkin also found that some brands consistently appeared in 55–77% of responses — proving that canonical strength cuts through the noise.
Multiplicity is the weather; continuity is the climate.
Immersion vs. Extractability
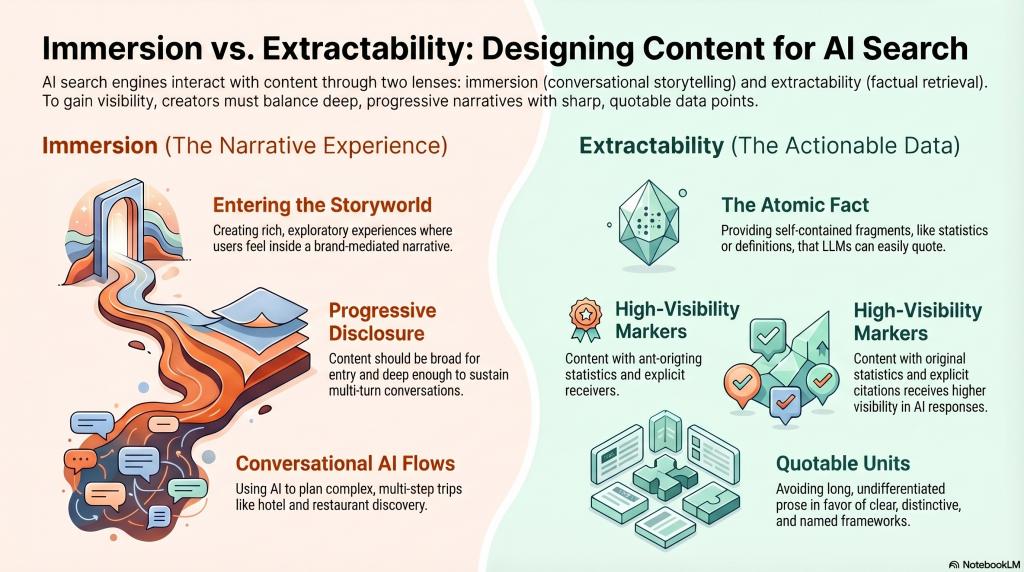
Immersion is about entering the storyworld, which are experiences so rich that users feel inside the narrative.
Extractability is about taking elements of the storyworld out into the real world (think action figures, memes, catchphrases).
In AI search, immersion maps to the conversational, exploratory experiences that AI Mode and ChatGPT provide.
When a user asks, “Help me plan a trip to Sardinia,” and the AI responds with a multi-turn conversation covering flights, hotels, restaurants, and hidden beaches, that’s immersion in a brand-mediated narrative. The brands that get cited in those immersive flows are the ones whose content is structured for progressive disclosure: broad enough to be the entry point, deep enough to sustain follow-up questions.
Extractability is the more immediately actionable principle. It answers the question: “How do I provide the atomic fact an LLM will quote?“
LLMs extract fragments (a statistic, a definition, a distinctive claim, a named framework). Content that provides clear, quotable, self-contained factual statements gets cited.
Content that buries insights in long paragraphs of undifferentiated prose does not. The data consistently shows that content with original statistics, named sources, and explicit citations gets higher visibility in AI responses, and not because of some trick, but because LLMs need extractable units to quote with confidence.
Worldbuilding
This is the cornerstone principle, the one that holds all others together.
In transmedia theory, the storyworld is the coherent universe within which settings, characters, objects, events, and actions exist. It has internal rules, consistent geography, and a “story bible” that serves as the canonical reference, ensuring all extensions remain coherent.
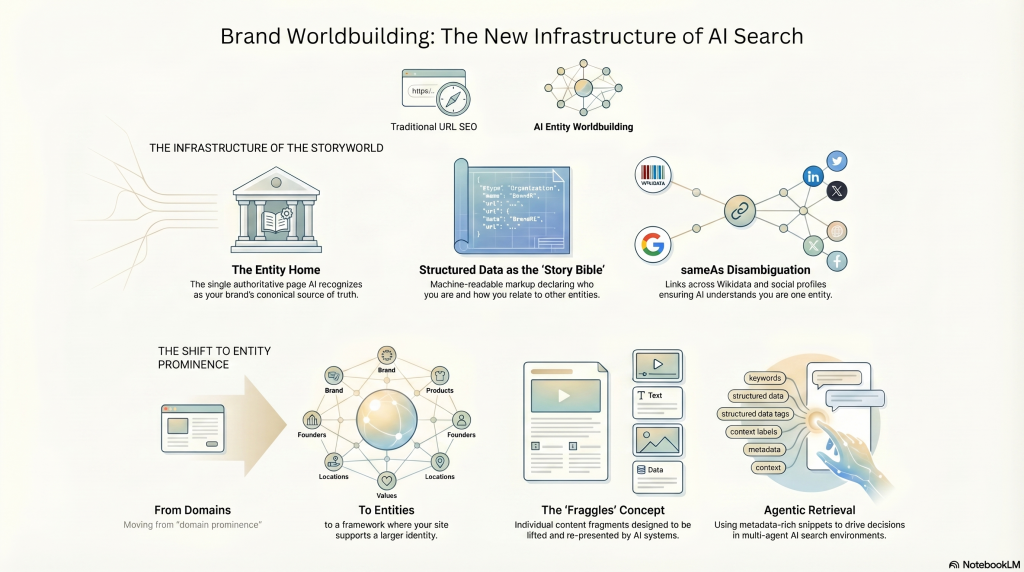
For brands in AI search, the storyworld is the entity architecture, and the “story bible” is a real, machine-readable infrastructure.
The brand storyworld has concrete components:
- The Entity Home (Barnard’s term) is the single authoritative page Google and other AI systems recognize as the canonical source of truth about your entity; your mothership, in Jenkins’ transmedia vocabulary.
- The Knowledge Graph presence — the entity node in Google’s Knowledge Graph, linked to Wikidata and Wikipedia — is the storyworld’s canonical identity.
- Structured data (Schema.org markup Organization, Brand, Person, Product, Article) is the machine-readable story bible, declaring who you are, what you do, and how you relate to other entities.
- The sameAs links — connecting your entity across Wikidata, Wikipedia, social profiles, and industry databases — are the cross-references, the disambiguation layer that ensures every AI system understands you are one entity, not several.
Andrea Volpini of WordLift has mapped the technical evolution this demands: from basic RAG (Retrieval-Augmented Generation) linking LLMs to vector databases, to agentic retrieval where metadata-rich snippets drive decisions about which URLs to open, to multi-agent systems where specialized AI agents collaborate.
His finding is decisive: sites with comprehensive structured data appear accurately in AI responses; those without risk being misunderstood or ignored entirely (see this paper he cosigned with Elie Raad, Beatrice Gamba, and David Riccitelli).
Cindy Krum of MobileMoxie identified the foundational shift years before most of the industry. Summarizing what she shared for years now, Google has moved beyond URL-based indexing into an entity-first era. This requires a shift from ‘domain prominence’ to ‘entity prominence’; a framework where your site is viewed as just one supporting element of a larger, verifiable brand identity.
Her “Fraggles” concept (Fragment + Handle) describes how Google indexes individual fragments of page content and organizes them around Knowledge Graph nodes — content designed to be lifted and re-presented.
This is exactly what AI does: it lifts narrative fragments, not whole pages. If your storyworld isn’t built in liftable, entity-anchored fragments, AI will lift someone else’s version of your story instead.
Seriality
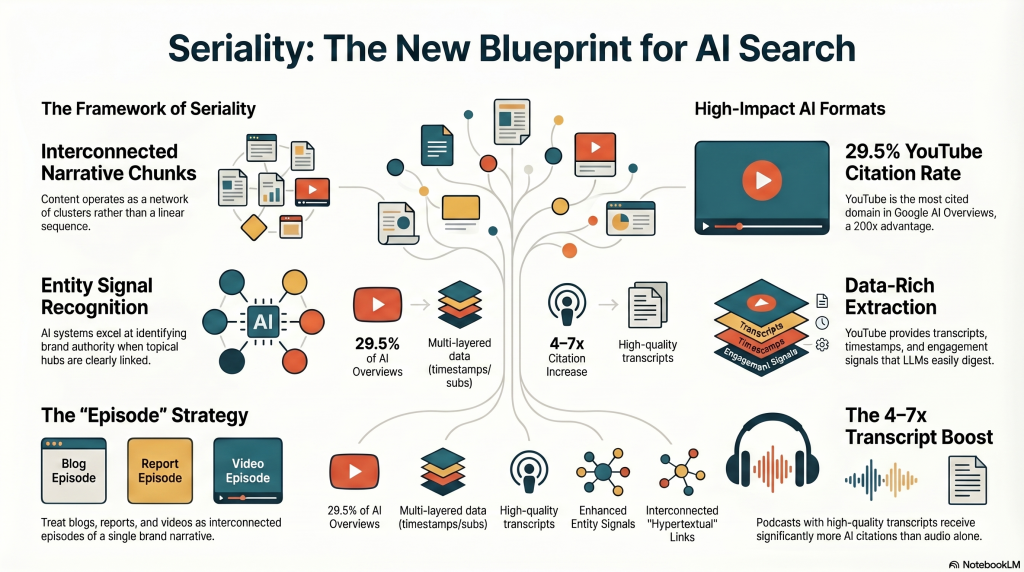
Jenkins described seriality as dispersing narrative chunks across multiple media in an interconnected sequence. Not a linear, but a hypertextual network.
In AI search, seriality operates through content clusters, topical hubs, and interconnected entity graphs.
A YouTube series on the brand’s core topic, a podcast exploring it from different angles, a blog cluster deepening the subtopics, a data report anchoring the whole structure, all these are the “episodes” of the brand’s serial narrative, and AI systems are remarkably good at recognizing their interconnection when entity signals are clear.
YouTube deserves special attention here. YouTube is now the single most cited domain in Google AI Overviews — up to 29.5% of AI Overviews cite YouTube, a 200x advantage over the nearest video competitor.
Even non-Google AI platforms cite YouTube almost exclusively for video content, and it is easy to understand if we consider how YouTube provides multi-layered data for AI extraction: transcripts, subtitles, chapter timestamps, comments, engagement signals, and all from a single source. If your brand’s serialized narrative doesn’t include YouTube, you’ve left the most powerful “episode format” off the table.
Podcasts are the emerging serial format for AI. Podcasts with high-quality transcripts receive 4–7x more AI citations than those without. The practical distinction matters: show notes are for listeners; transcripts are for AI. A podcast transcript is first-party data you own and control, structured in a conversational format that LLMs handle natively.
If you’re producing expert interviews, roundtables, or thought leadership audio, transcribing it is no longer optional.
Subjectivity

In transmedia storytelling, subjectivity means exploring the storyworld through different characters’ perspectives — the same events seen through different eyes, enriching the narrative.
For AI search, subjectivity maps to the diversity of voices that contribute to a brand narrative.
The data is striking: 85% of brand mentions in AI come from third-party sources, not from the brand’s own domain, as for this report by AirOps.
Each source brings a different perspective: a reviewer’s experience, a forum user’s complaint, an industry analyst’s assessment, a journalist’s profile, an employee’s LinkedIn post.
This is where E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) becomes a transmedia concept, not just an SEO checklist.
The brands with the strongest AI visibility are those whose story is told by multiple credible voices: named experts attached to content, recognizable authors with their own entity presence, customer voices on review platforms, and industry recognition from awards and rankings. Each is a “character” contributing a subjective perspective that enriches the brand’s storyworld.
The strategic implication: your content strategy must extend beyond your own domain. Earning mentions on Reddit, citations in industry publications, reviews on G2 or Trustpilot, author bylines on third-party sites, these are all “subjective entries” into your brand’s storyworld, and AI systems weigh them heavily precisely because they come from independent perspectives.
Performance

This was always the most radical of Jenkins’ principles; the idea that fans (the prosumers) don’t just consume the storyworld but actively extend it, and that their performances become part of the narrative ecosystem.
In the AI Search age, performance has been amplified beyond anything Jenkins described, and beyond what I anticipated in 2013.
Users now remix brand narratives through AI itself. Custom GPTs in the GPT Store allow anyone to create brand-specific AI assistants trained on brand guidelines; each one is a user-remixed version of the brand narrative.
AI-assisted UGC Platform Market is expected to be a $4.4 billion market in 2030, growing at 29.4% annually, as indicated in this market analysis report by Grand View Research.
But the most consequential “performance” is happening in AI-mediated product discovery.
The interaction model is fundamentally performative: the user describes a need conversationally, the AI performs brand evaluation, comparison, and recommendation, and the user co-constructs the purchase decision through a dialogue where the brand is discussed but not present.
The recent “failure” of ChatGPT’s Instant Checkout — scaled back in March 2026 after near-zero purchase conversions — actually proves the transmedia point. Users didn’t want to buy inside the AI. They wanted the AI to tell them a story about what to buy and then go purchase it, where they already trusted the transaction. OpenAI retreated from storefront to stage.
The AI surface is not a shop; it is a narrative medium where brand stories are performed, evaluated, and retold. That makes the brand narrative on those surfaces more important, not less, because the story the AI tells is the last thing the user hears before they go buy.
OpenAI’s system explicitly considers Reddit discussions more trustworthy than paid marketing in this discovery context. Walmart, Target, and Instacart all integrated with ChatGPT as referral partners, and Google launched Universal Commerce Protocol in January 2026 to standardize AI-to-retailer handoffs. The direction is clear: AI surfaces own the narrative; retailers own the transaction. If your brand’s story isn’t coherent on the narrative side, you lose the customer before they ever reach the transaction.
The consensus-information gain engine

Understanding the seven updated principles is necessary. But there’s a dynamic operating beneath all of them that determines which brands actually get cited and which ones get synthesized into generic background noise.
I call it the consensus-information gain axis, and it is the engine driving brand differentiation in AI search.
Consensus is what most sources agree on.
LLMs are consensus-synthesis machines, and they excel at aggregating what the internet collectively believes.
If 50 sources say the same thing about a topic, the LLM will confidently present that as established knowledge. This is the continuity and spreadability layer: your brand must be mentioned consistently across enough authoritative sources that AI treats your core facts as settled.
Information gain is the opposite force, aka unique, novel contributions that go beyond what competitors cover.
Google had been granted a patent for an “information gain score” in June 2022 (which was filed in 2018), explicitly measuring how much new information a document adds beyond what existing results already provide. If two sources say the same thing, the model picks one arbitrarily; if you say something new, you get cited by name.
Bernard Huang of Clearscope puts it precisely in these two articles:
- How to Rank SEO Content in the Era of Generative AI.
- How to Add Information Gain to Your Content: 3-Phase Plan
Paraphrasing Bernard, AI can serve up consensus content to answer a query, but it cannot generate original interviews, survey data, proprietary product reviews, or genuinely new perspectives. Those are the province of the source, and the LLM must cite the source to include them.
Brands must simultaneously build consensus signals — mentioned consistently across Reddit, G2, YouTube, listicles, review platforms — so LLMs recognize them as category players, AND produce information-gain content — proprietary data, contrarian views, original research, named frameworks — so they get cited as unique sources.
This maps directly to the transmedia tension between continuity and multiplicity, between spreadability and drillability.
Your canonical facts must be everywhere (consensus), at the same time, your original insights must be distinctive enough to be worth extracting (information gain).
Harvard Business Review, writing in March 2026, framed the strategic implication directly: companies must shift from optimizing pages for clicks to engineering recall inside AI systems; publishing original data, naming proprietary frameworks, and attaching credentialed experts to insights.
The Ahrefs “Xarumei” experiment (about which I wrote extensively here) showed how this works in practice, and how it can go wrong.
Ahrefs created a fictional luxury brand, then tested 56 questions about it across eight AI models. When fake stories were planted on Reddit, Quora, and Medium, AI models began confidently repeating false narratives about a brand that didn’t exist. The most detailed story won, even when false.
The lesson is symmetrical: if the most detailed, consistent, information-rich narrative about your brand is one you didn’t create, that’s the one AI will tell.
The storyworld is the strategy
 Spotify evolved “Wrapped” from a data summary into a physical-digital narrative world.
Spotify evolved “Wrapped” from a data summary into a physical-digital narrative world.
In late 2025, they built 50 “Fan Destinations” worldwide—massive physical installations based on the year’s top musical “lores.”
If you were a top listener for an artist like Chappell Roan or Lady Gaga, your app gave you “coordinates” or “keys” to unlock specific physical interactions at these sites (like the 800-foot red hair cascade in NYC). It transformed streaming data into a “quest” for the physical world.
Let me bring this full circle.
In 2013, I spoke about the concept of a “Transmedia Bible” for brands (see also this old slide deck), a strategic document that includes premise, expansion, theme, audience, narrative synthesis, business model, and specifications. I referenced the Halo Story Bible as the exemplar: a canonical reference ensuring every game, novel, comic, and film stayed consistent within the Halo universe.
In 2026, the Transmedia Bible is not a document but infrastructure.
- Your Entity Home is the mothership, aka the canonical source from which all narrative extensions radiate.
- Your Knowledge Graph presence is the canonical identity or, in other words, the entity node that every AI system references to understand who you are.
- Your structured data is the machine-readable story bible, or the Schema.org declarations, that tell AI systems your name, your category, your properties, and your relationships.
- Your sameAs links are the cross-references; the disambiguation layer ensures you are recognized as one coherent entity across all databases.
- Your content corpus is the canonical narrative; the episodes, chapters, and entries in your serialized storyworld.
- Your visual assets are the visual language, which is controlled through what Myriam Jessier calls the “Object Bible“, ensuring consistent imagery AI can associate with your entity.
- Your third-party mentions are the subjective entries; the independent voices confirming and enriching your story.
- Your community signals — Reddit threads, forum discussions, review platforms — are the performances, the co-created extensions that AI systems treat as some of the most trustworthy evidence of all.
Together, these components constitute your brand’s storyworld in AI search. And the brands that win are the ones that manage this storyworld with the same rigor a franchise showrunner applies to a multi-billion-dollar entertainment universe.
From storyteller to architect
 Recognizing that the film’s core theme is “Anyone can wear the mask,” Sony launched an AI-powered “Spidersona” generator. Fans didn’t just watch Miles Morales; they created their own Spiderman versions that looked like the film’s unique art style.
Recognizing that the film’s core theme is “Anyone can wear the mask,” Sony launched an AI-powered “Spidersona” generator. Fans didn’t just watch Miles Morales; they created their own Spiderman versions that looked like the film’s unique art style.
They created a “Spider Society” via SMS and social media, sending “leaked” documents and multiversal alerts to fans. It turned the audience into an active army of variants rather than just consumers.
There’s a deeper shift happening that the transmedia framework helps us see.
When I wrote the 2013 post, the SEO’s role was already evolving from keyword optimizer to content strategist.
The transmedia lens pushed that further, toward brand storyteller.
Now, the role is evolving again.
The AI search reality requires something more like an architect than a storyteller. Architects don’t just design buildings; they design the systems, constraints, and structural logic that ensure the building holds together.
They think in terms of load-bearing walls, material properties, environmental forces, and human traffic flows.
The building must be coherent internally, functional for its inhabitants, and resilient to forces the architect cannot control.
That’s exactly what AI Search SEO demands.
We are designing the structural logic — the entity architecture, the knowledge graph presence, the content topology, the cross-platform consistency — that ensures AI systems can reliably reconstruct our brand narrative even when we are not in the room.
Even when the AI is pulling from sources we didn’t create. Even when the user is asking questions, which we didn’t anticipate. Even when a different AI engine, with different retrieval preferences, is telling our story to a different audience.
Jenkins always insisted that transmedia storytelling was not about adaptation, which consists of taking the same content and reformatting it for different platforms.
It was about extension: each platform contributing something unique to a coherent whole.
That distinction matters more than ever.
The brands losing in AI search are the ones adapting (repurposing the same blog post across channels).
The brands winning are the ones extending and building a coherent entity architecture where each platform — YouTube, podcast, blog, schema markup, Wikipedia, Reddit presence — contributes a unique, additive layer to a unified narrative.
The storyworld is the strategy. The entity is the protagonist. The Knowledge Graph is the canon. Structured data is the story bible. And AI search engines are the audience that never stops reading, never stops synthesizing, and never asks for your permission to retell your story.
You’d better make sure they tell it right.
