

The most important sentence about the future of Search in 2026 wasn’t delivered at a product launch or an earnings call. It came over a pint.
On April 7, Sundar Pichai sat down with Stripe co-founder John Collison and investor Elad Gil on the Cheeky Pint podcast for a 72-minute conversation about Google’s AI trajectory (here you find the transcript). There were no product announcements. No slides. No rehearsed talking points about “organizing the world’s information.” Instead, Pichai offered something more consequential: a quiet redefinition of what Search actually is.
The key line: “If I fast-forward, a lot of what are just information-seeking queries will be agentic in Search. You’ll be completing tasks. You’ll have many threads running.” And then, the framing that ties it together: “Search would be an agent manager.”
That’s not iteration but an architectural declaration. And it’s backed by between $175 billion and $185 billion in planned 2026 capital expenditure (Alphabet Q4 2025 earnings, Feb 4, 2026), which nearly doubles the $91.4 billion spent in 2025. Pichai also named 2027 as “an important inflection point” for agentic workflows and confirmed that Google’s internal agent platform, Antigravity, had been deployed to the Search team the week before the interview. The company building Search is already using agent orchestration tools internally. The consumer product will follow.
For those of us working in SEO, growth, and digital commerce, the interview demands close reading; not just for what Pichai said, but for what he deliberately avoided saying. In 72 minutes about the future of Search, the CEO of Alphabet made no binding commitment on publisher economics, content-creator attribution, ads monetization within AI surfaces, or the antitrust implications of Chrome as an agentic distribution platform. The silences are as strategic as the statements.
This article synthesizes my thoughts and analyses of the interview, cross-verified against primary sources including patents, earnings data, Google’s own documentation, and third-party industry research. The goal is straightforward: decode what’s actually being built, separate the verifiable from the speculative, and translate it into strategic decisions you can act on in 2026.
Let me walk you through it.
What Pichai actually said… and what he carefully didn’t
Pichai organized the interview around three threads:
- A defensive re-narration of Google’s AI history.
- A bullish thesis on AI’s non-zero-sum economics.
- An unusually specific articulation of supply constraints.
Taken together, they form a coherent strategic signal that is not a product roadmap but a declaration of architectural intent.
Here are the statements that matter most for anyone building a strategy around Search.
The “agent manager” framing is Pichai’s new thesis for what Search becomes. He described a future where information-seeking queries are agentic, or, said in other words, where Search doesn’t return answers but orchestrates tasks across multiple parallel threads. He also said that Search and Gemini will “overlap in certain ways” and “profoundly diverge in certain ways.” Translation: both products persist, neither subsumes the other in 2026, but Search’s gravitational center is shifting from retrieval to orchestration.
Gemini 2.5 was the perception inflection; Gemini 3 validated the full stack. Pichai identified Gemini 2.5 as the model “where people saw it”, which is a tacit concession that earlier versions didn’t change market perception. He now claims full-stack advantage: seventh-generation custom TPUs, Flash-tier models delivering what he described as 90% of the capability of the Pro models at a fraction of serving cost, and open-weights Gemma 4 that can run on consumer hardware.
Search latency improved by over 35% in five years while AI capabilities were added. Sub-teams within Search operate with latency budgets of 10 to 30 milliseconds. When a team shaves 3 milliseconds off a process, 1.5ms goes back to the team for new features, and 1.5ms goes to users as faster load times. This isn’t simple trivia, but the organizational mechanism that makes Flash-tier Gemini viable as the default AI Mode model at a global scale.
2026 is the diffusion year; 2027 is the agentic inflection. Pichai was explicit: he expects 2027 to be “a big year in which some of those shifts happen pretty profoundly.” He estimates that today, only about 0.1% of the world “is living this future.” The bottleneck isn’t model quality but identity, access controls, permissions, and change management. The infrastructure for who agents are allowed to be and what they’re allowed to do is what’s gating mass deployment.
Supply is the binding constraint, and Pichai ranked it. His ordered bottleneck list:
- Wafer starts.
- Memory — “No way that the leading memory companies are going to dramatically improve their capacity”.
- Data-center permitting
- Electricians.
He personally reviews the compute allocation by project weekly. This is why Flash-tier economics dominate the roadmap and why Google is exploring long-term hedges, including data centers in space.
Consumer agents are on the roadmap but still gated. Pichai described bringing agentic capabilities to consumers as “an exciting frontier we are looking at,” which, in corporate-speak, means it’s planned but not imminent for the mass market. Project Mariner, Chrome auto-browse, and AI Mode’s native agentic handoff for tickets and reservations are the pilots. The broad deployment is 2027.
Antigravity is already inside the Search team. Pichai confirmed that the internal agent platform — known as Jet Ski before being renamed Antigravity — had been deployed to the Search team the week before the interview. This matters more than it might seem at first glance. If the organization that builds Search starts working with agent orchestration tools, it’s reasonable to expect the product itself to reflect that architecture. The consumer version of Search is being rebuilt in the image of Google’s internal agent workflows.
The non-zero-sum framing is a pre-emptive defense. Pichai repeated variations of the same argument multiple times: “YouTube has done well since TikTok,” “Amazon has done well since Google.” This is rhetorical scaffolding for investors and regulators who worry that AI Mode cannibalizes the referral traffic that built the open web. It’s a reasonable argument in theory. But notice what he paired it with: no commitment whatsoever to publisher economics.
A post-training breakthrough is pending. Pichai hinted at unreleased research — “I don’t want to be specific about the second one, but we’ll publish it one day” — that will likely produce a visible quality jump in 2026. This is worth watching for at Google I/O in May.
The security warning was unusually direct. “These models are definitely really going to break pretty much all software out there. Maybe already, we don’t know. There will be a moment of… It could be a sharp moment.” That’s the most downside-oriented public statement Pichai has made about AI risk. It’s not simply hypothetical but a near-term operational concern.
There’s also one analogy worth pulling out, because it reveals how Pichai thinks about Google’s competitive position. He compared the evolution of Search to Waymo: not a single model breakthrough, but patient capital, system integration, proprietary hardware, safety validation, and disciplined deployment over years. Waymo didn’t win by having one better algorithm. It won by compounding advantages across the full stack. That’s exactly how Pichai frames Search: models alone don’t win; the combination of data, infrastructure, browser, maps, Knowledge Graph, Shopping Graph, identity systems, and product feedback loops creates a compounding advantage that no single-product competitor can replicate.
What Pichai carefully didn’t say
A senior SEO reading this interview should treat the silences as the real story.
In 72 minutes about the future of Search in April 2026, the CEO of Alphabet did not address: publisher traffic impact from AI Overviews, content-creator economics or attribution mechanisms in AI Mode, ads monetization strategy within Gemini or AI surfaces, Chrome’s role as an agentic distribution platform, Android as an AI distribution channel, or the DOJ, CMA, and EU antitrust proceedings that directly affect how these products can be deployed.
He was asked about Google Docs search being poor and committed to “sharp improvements in the coming months.” He was not asked — and did not volunteer — anything about the web ecosystem that provides the content his AI systems synthesize.
That’s not an oversight. When a CEO spends an hour describing a future where Search becomes an agent manager while $175–185 billion flows into agentic AI infrastructure, and declines to make a single binding statement about the publishers and businesses that feed the system, that’s a strategic position. It tells you where the company’s priorities are, and where they aren’t.
Three Searches, not one: the architecture being built
One of the clearest takeaways from cross-referencing all three research reports is that we’re no longer talking about a single Search product evolving. We’re looking at three distinct surfaces that will coexist, each serving different intent types, each with different economics, and each requiring a different strategic response.
Understanding which surface handles which intent — and how traffic, citations, and transactions flow through each — is the foundation for every tactical decision that follows.
The first surface is classic Search. It persists, and it will continue to matter for navigational queries, brand searches, transactional intent, and cases where the best experience is still sending the user to a specific URL. Google’s own documentation on AI features in Search states that AI Overviews only appear when Google’s systems determine they add value over classic results, and that if confidence in the quality of a generative response is insufficient, the system reverts to showing web links.
The data confirms this isn’t disappearing overnight. According to BrightEdge’s February 2026 analysis, approximately 52% of tracked queries still trigger no AI Overview at all. For the majority of searches, organic rankings remain the entire experience. But the trajectory is clear: that 52% is shrinking. A year earlier, the no-AIO rate was closer to 70%. Classic Search is becoming the fallback, not the default — and the transition is accelerating faster in some verticals than others.
BrightEdge’s data is confirmed by the one offered by Advanced Web Ranking for April 13, 2026, by its free Google AI Overview Tool:

The second surface is the exploration and reasoning layer: AI Overviews and AI Mode. This is where the fan-out architecture operates. When a user enters a complex query, the system decomposes it into multiple sub-queries, fires them in parallel against the web index, Knowledge Graph, Shopping Graph, Maps, and YouTube, and synthesizes a cited response. Google’s own AI Mode blog post describes this query fan-out mechanism explicitly.
The numbers tell the story of how rapidly this layer is expanding. BrightEdge data shows AI Overviews now appear on roughly 48% of all tracked queries, a 58% increase year-over-year. The expansion is uneven across verticals: healthcare leads at 88%, education at 83%, B2B technology at 82%, and restaurants at 78%. Ecommerce and finance remain lower, partly because Google is more cautious with high-commercial-intent queries where ad revenue is at stake.
What’s most strategically significant is the citation gap between this layer and traditional organic rankings. BrightEdge found that only about 17% of sources cited in AI Overviews also rank in the organic top 10. That number has been remarkably flat, barely moving over the entire tracking period. For AI Mode specifically, SE Ranking’s August 2025 analysis found only 14% of cited URLs rank in the top 10. Five out of six AI citations are pulling from content that isn’t on page one of traditional results. Ranking and being cited are connected systems, but they operate on different logic.
The zero-click data reinforces the point. Traditional Google searches end without a click roughly 60% of the time. When AI Overviews are present, that rate climbs to approximately 83%. In AI Mode, it reaches 93% according to Semrush’s September 2025 data. And Pew Research found that only about 1% of users click on links inside an AI Overview. The user gets the answer and moves on.
The third surface is agentic Search, aka the execution layer. This is where Pichai’s “agent manager” vision becomes concrete. Search no longer just explains; it acts.
Google has already shipped this in several forms. Project Mariner runs cloud-hosted Chrome VMs for AI Ultra subscribers ($249.99/month) and can handle up to 10 parallel browsing tasks. Chrome’s “auto browse” feature, launched in January 2026 for US AI Pro/Ultra users, completes form-filling, research, reservations, and bookings across tabs through a persistent side panel. AI Mode itself has native agentic handoff for tickets via Ticketmaster and StubHub, restaurant reservations via Resy, and local appointments via Vagaro. Search can now call local businesses to verify prices and availability on the user’s behalf.
The commerce layer closes the loop. The Universal Commerce Protocol (UCP), launched at NRF in January 2026 with Shopify, Etsy, Wayfair, and Target, establishes a common standard for agents to discover products, negotiate fulfillment, and execute secure checkout. The transaction happens within Google’s surfaces using stored payment credentials. The merchant remains the merchant of record, but the browsing-to-buying journey never leaves Google’s ecosystem.
But UCP only covers commerce. The broader web — forms, bookings, support tickets, data queries — still required agents to navigate visual interfaces designed for human eyes, clicking buttons and scraping DOM elements like a human pretending to be a machine pretending to be a human. That problem now has a proposed solution.
In February 2026, Google released an early preview of WebMCP (Web Model Context Protocol), a new web standard developed jointly with Microsoft engineers through the W3C’s Web Machine Learning Community Group (Chrome for Developers, Feb 10, 2026). WebMCP allows websites to expose their functionality as structured, callable tools directly to AI agents through a new browser API: navigator.modelContext. Instead of an agent taking screenshots and guessing where to click, a WebMCP-enabled website tells the agent exactly what tools are available and how to use them.
The protocol offers two APIs: a Declarative API that translates standard HTML forms into machine-readable schemas using attributes like toolname, and an Imperative API that lets developers register more complex interactions via JavaScript. A flight booking site, for example, wouldn’t need the agent to navigate its visual interface, but it would expose a book_flight({ origin, destination, date }) tool that the agent calls directly. As Search Engine Land reported, Dan Petrovic called it “the biggest shift in technical SEO since structured data.” It’s currently available in Chrome Canary behind a flag, with broader rollout expected through 2026.
Alongside WebMCP, Google formalized the identity of its agent traffic. On March 20, 2026, a new user agent called Google-Agent was added to Google’s official fetcher list. Unlike Googlebot, Google-Agent only visits a site when a human user specifically directs an AI agent to perform a task — making it a user-triggered fetcher, not a crawler. And unlike OpenAI’s and Anthropic’s equivalent fetchers, Google-Agent ignores robots.txt by design, because Google treats it as a proxy for the user, not an autonomous bot (Semrush, March 2026). Project Mariner is the first product using it. For site owners, this creates a new traffic category that doesn’t appear in traditional analytics and can’t be blocked through conventional means. You need to track it in server logs and prepare your infrastructure accordingly.
There’s a useful way to think about this entire progression: we’ve moved from a Link Economy to an Answer Economy and are now entering an Action Economy. In the Link Economy, Search found the best page. In the Answer Economy, Search synthesized the best response. In the Action Economy, Search completes the task, and UCP, WebMCP, and Google-Agent are the technical plumbing that make it work. Each transition reduces the user’s need to visit external sites and increases Google’s intermediation of the journey from intent to resolution.
One more structural shift worth noting: Search is no longer confined to the search results page. In early 2026, Google made Gemini 3 the default model for AI Overviews and enabled seamless transitions from AI Overviews into full AI Mode conversations. In April 2026, AI Mode began operating as a side panel within Chrome, sitting alongside web pages without requiring a tab switch. Search Live expanded globally, bringing multimodal voice and camera interaction to over 200 countries. The search box isn’t dying, but the act of searching increasingly looks less like typing a query and more like having an ongoing conversation with a system that can see, hear, remember, and act.
As Google’s own Search Central documentation notes, AI Overviews and AI Mode can surface a broader and more diverse set of links than a classic web search, precisely because they explore sub-queries and alternative sources that a traditional SERP wouldn’t show. That’s good news for high-quality content that wasn’t making it to page one. But it also means that the competitive landscape is wider, less predictable, and fundamentally different from what most SEO strategies are built to address.

The infrastructure nobody’s talking about: graphs, compression, and why they determine who gets cited
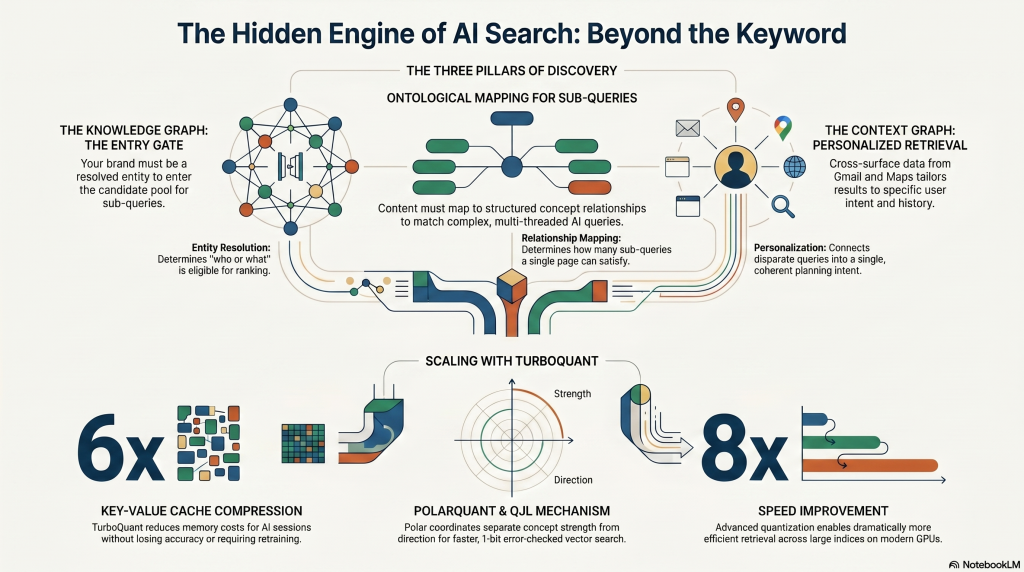
Most of the industry conversation about AI Search focuses on the visible layer: AI Overviews, AI Mode, citation counts, and zero-click rates. That’s understandable, because that’s where the impact shows up in dashboards. But underneath the surface, there’s an infrastructure layer that determines whether your content enters the candidate pool at all, and it has very little to do with keywords or even traditional ranking signals.
Pichai never used the words “Knowledge Graph” or “ontology” in the interview. Not once. But every product capability he described — fan-out sub-queries, personalized retrieval, multi-threaded agent tasks, persistent context across sessions — has a direct architectural dependency on structured knowledge representations. The silence on this topic is itself revealing, because it suggests Google treats this infrastructure as so foundational that it doesn’t need to be discussed publicly. It just runs.
Let me connect the layers.
The Knowledge Graph is the entity resolution layer, and it operates upstream of everything else. When AI Mode decomposes a query into sub-queries, entity disambiguation happens before passage retrieval. The system first resolves “who or what is this about” and only then retrieves relevant passages from the web index. This means that if your brand, your product, or your expertise isn’t a resolved entity in Google’s Knowledge Graph, you’re not in the candidate pool for fan-out sub-queries. You’re invisible at the stage where it matters most: before ranking even begins.
This isn’t speculative. Google’s Shopping Graph, Maps data, YouTube metadata, and the web index all feed into AI Mode’s fan-out architecture. The patents examined across the three research reports — including the pairwise passage ranking patent and the user embedding patent (WO2025102041A1) — show that entity resolution is the entry gate for the entire retrieval pipeline.
The ontological layer determines how many sub-queries surface your content. When AI Mode breaks “best family beach holiday in July” into 8 or 12 sub-queries covering geography, accommodation types, traveler profiles, seasonal factors, pricing tiers, and activity availability, it’s following an implicit ontology, aka a structured map of how concepts in that domain relate to each other. If your content architecture maps to this ontological structure, your passages become retrievable across multiple sub-queries from a single parent query. If your architecture is flat and keyword-driven, you might match one sub-query and miss the rest.
Think of it this way. A traditional SEO approach would optimize one landing page for “best family beach holiday in July.” An ontologically structured approach would ensure that the site’s information architecture covers the entity relationships the fan-out expects: destination entities with climate attributes, accommodation types with family-suitability properties, activity entities with age-range constraints, and pricing entities with seasonal variation. The hub document establishes these relationships. The supporting content provides passage-level answers to the specific questions each sub-query generates. That’s what makes a site citable across multiple branches of a single fan-out, rather than once or not at all.
The Context Graph is the personalization layer — and it’s what makes the same query produce different results for different users. User embedding patent (WO2025102041A1) confirms that identical queries can generate different sub-queries and surface different sources depending on the user. The system doesn’t just ask “what is this about” (Knowledge Graph) and “how do things relate” (ontology), but it asks “what does this mean for this specific user right now.” When agents execute tasks across parallel threads, the Context Graph maintains coherence across those threads, connecting a search for “Tenerife family resort” with a subsequent query about “flights from Valencia” as a single planning intent. That’s contextual entity linking, not keyword matching.
Google has a structural advantage here that no competitor currently matches. Search history, Gmail, Maps, YouTube, Chrome, Android, Photos, all feed a unified cross-surface Context Graph. Pichai’s references to identity, permissions, and personal context throughout the interview point directly to this layer. It’s also why he described Personal Intelligence — the opt-in feature connecting Gemini to your Google apps — as a strategic priority rather than a convenience feature.
Now here’s where the economics come in, and why TurboQuant matters.
Everything I’ve just described — fan-out sub-queries, multi-threaded agent tasks, personalized retrieval, persistent context — multiplies the computational cost per query by an order of magnitude compared to classic Search. Each parallel agent thread needs its own key-value cache. Each follow-up turn in a conversational session extends that cache. Each personalization pass adds another retrieval step. At Google’s query volume, the memory cost of running this architecture for free-tier users is prohibitive without aggressive compression.
TurboQuant is the algorithmic answer to that exact constraint. Published by Google Research on March 24, 2026, and presented at ICLR 2026, it compresses the key-value cache — the running memory that allows a model to maintain context without re-reading everything from scratch — by a factor of 6×, down to just 3 bits per value, with no loss in accuracy and no retraining required.
It works through two components. PolarQuant handles the primary compression by converting data vectors into a polar coordinate representation — separating the strength of a concept from its semantic direction — which makes the data’s shape predictable enough to compress without expensive normalization overhead. QJL then acts as a 1-bit error checker on whatever small distortion PolarQuant introduced, requiring zero additional memory. The result: up to 8× speed improvement over unquantized keys on H100 GPUs, and dramatically more efficient vector search across large indices.
Map this onto Pichai’s interview, and three connections become clear.
First, TurboQuant is how agentic capabilities scale from paying tiers to all users. AI Mode itself is available to everyone, but the heavier agentic features — multi-step task execution, persistent context, parallel agent threads — remain gated to AI Pro and Ultra subscribers. Pichai said that 99.9% of the world isn’t “living this future” yet. The per-query memory cost of those agentic workflows needs to converge toward the cost of a simple single-turn query before that changes. TurboQuant is one of the compression layers that gets Google there.
Second, it directly powers the vector search layer that determines which passages and entities get retrieved. When AI Mode fires sub-queries against the web index and Knowledge Graph, each retrieval step is fundamentally a vector similarity search. If that search is 6–8× cheaper per lookup, Google can afford more sub-queries per parent query with deeper passage-level retrieval. That means ontological coverage — answering more of the sub-queries the fan-out generates — becomes even more critical for visibility.
Third, TurboQuant bridges the gap between Pichai’s “30× more efficient” target and the 2027 inflection point. Combined with Flash-tier model distillation, mixture-of-experts architectures, and TPU v6 hardware, it’s one of the compression layers that moves persistent consumer agents from “someday when compute gets cheap enough” to “2027, with the math already solved.”
The practical consequence is counterintuitive: extreme compression doesn’t make AI Search simpler, but deeper. When each query costs less to process, Google doesn’t pocket the savings. It spends them on more sub-queries, longer context windows, more personalized retrieval, and more agentic task chains. The brands that have built ontological depth across multiple facets of their domain get cited repeatedly. The brands with a thin keyword-optimized landing page get cited zero times, because there’s now a cheaper, more thorough alternative passage from a competitor that actually covered the sub-query.
The window to build this structural depth is narrowing. TurboQuant doesn’t change what you need to do strategically; it accelerates when the strategic shift becomes non-optional.
The security frontier: when the Web becomes a weapon against its own agents
Pichai’s security warning in the interview was unusually direct for a CEO who typically speaks in measured corporate language: “These models are definitely really going to break pretty much all software out there. Maybe already, we don’t know. There will be a moment of… It could be a sharp moment.”
That’s not a hypothetical concern about some distant future. It’s an acknowledgment that the agentic infrastructure Google is building — agents that browse, transact, fill forms, and execute multi-step workflows on behalf of users — creates attack surfaces that didn’t exist when Search was just returning links.
Google’s own research arm has been mapping exactly how dangerous those surfaces are. On March 8, 2026, researchers at Google DeepMind published the first systematic framework for what they call “AI Agent Traps” — adversarial content embedded in web pages and digital resources specifically designed to manipulate, deceive, or exploit autonomous AI agents (SSRN, March 2026).
The paper identifies six classes of attack, each targeting a different component of an agent’s operational architecture:
- Content Injection Traps exploit the gap between what a human sees on a page and what an agent parses. Hidden instructions can be embedded in HTML comments, invisible CSS-positioned text, or metadata attributes, being completely invisible to human visitors but actively processed by AI agents.
- Semantic Manipulation Traps corrupt the agent’s reasoning through framing effects, emotionally charged language, and authoritative-sounding content that statistically skews conclusions.
- Cognitive State Traps poison an agent’s long-term memory or RAG knowledge base, altering its behavior on specific queries over time.
- Behavioral Control Traps directly hijack what the agent does, and the DeepMind researchers documented cases where a single manipulated email was enough to get an agent to bypass security classifiers and leak its entire privileged context.
- Systemic Traps target multiple agents simultaneously, potentially triggering cascading failures like coordinated sell-offs across AI trading systems.
- Human-in-the-Loop Traps turn the agent into a vector for attacking the human supervisor, aka generating truncated summaries or misleading recommendations designed to exploit approval fatigue.
The empirical evidence is sobering. According to the DeepMind paper and subsequent reporting, simple prompt injections embedded in web content commandeer agents in up to 86% of tested scenarios. Data exfiltration attacks exceeded 80% success rates across five tested agents. These aren’t theoretical vulnerabilities, but demonstrated exploits against current-generation systems.
This has direct implications for businesses implementing the agentic infrastructure discussed in the previous sections. If you’re adopting WebMCP to make your site agent-readable, you’re also creating structured tool interfaces that malicious actors could potentially exploit. If you’re implementing UCP endpoints for agentic checkout, you’re opening transactional pathways that need security auditing from a perspective most e-commerce teams haven’t considered yet. The same structured data that makes your site useful to legitimate agents also makes it a more predictable target for adversarial ones.
There’s also a legal accountability gap that the DeepMind researchers flagged explicitly: if a compromised agent executes a fraudulent transaction, current legal frameworks offer no clear answer for whether liability falls on the agent operator, the model provider, or the domain owner hosting the content that triggered the exploit. This is unresolved as of April 2026, and it will need to be addressed before agentic commerce can scale into regulated industries like finance, insurance, or healthcare.
For the security-conscious business owner or CMO, the practical takeaway is this: agent readiness is not just about making your site readable and transactable by AI systems. It also means auditing your content and infrastructure for vulnerabilities that only exist because agents interact with the web differently than humans do. The web was built for human eyes. It is now being rebuilt for machine readers. And as DeepMind’s research makes clear, not everyone building for that new audience has good intentions.
The uncomfortable economics: revenue grows while the Web that feeds it shrinks
There’s a tension at the center of everything Pichai described in that interview, and it’s worth stating plainly: Google’s Search ad revenue is growing at its fastest rate in years, while the publisher traffic that historically justified that revenue is collapsing. Both of these things are happening simultaneously, and they are not contradictory: they are the same strategy viewed from two sides.
The numbers are clear. Google Search revenue hit $63.07 billion in Q4 2025, up 17% year-over-year (Search Engine Journal, Feb 2026). Growth accelerated through every quarter of 2025 — from 10% in Q1, to 12% in Q2, to 15% in Q3, to 17% in Q4. Alphabet’s annual revenue exceeded $400 billion for the first time. Pichai attributed the growth directly to AI features driving more usage: “Search had more usage in Q4 than ever before.” Total advertising revenue for the quarter reached $82.3 billion, up 14% year-over-year.
On the other side of that equation, publisher click-through rates from AI-present queries are in steep decline. When AI Overviews appear, zero-click rates reach approximately 83%. In AI Mode, they reach 93%. Only about 1% of users click on links within an AI Overview. For news publishers specifically, the damage has been acute, and organic visits fell from over 2.3 billion in mid-2024 to under 1.7 billion by May 2025, while zero-click rates for news searches surged from 56% to 69%.
Google is already monetizing the AI surfaces that replace those clicks. Direct Offers — paid placements inside AI Mode — are live. Business Agent, which lets brands like Lowe’s and Poshmark run branded AI experiences directly within Search, is in testing. UCP-based agentic checkout embeds the transaction inside Google’s own interface. The ad formats are evolving to match the new architecture: instead of sending users to a merchant’s site, the ad facilitates discovery, comparison, and purchase without leaving Google’s ecosystem.
One patent deserves particular attention here because it reveals how far this intermediation could go. US12536233B1, granted on January 27, 2026, describes a system where Google scores a publisher’s landing page on bounce rate, click-through rate, conversion, and design quality. When the page falls below a quality threshold, Google substitutes an AI-synthesized landing page assembled from the organization’s product data, the user’s search history, and account context. The patent explicitly allows this synthesized page inside a sponsored placement, meaning Google could intermediate not just the search result but the landing experience itself. Glenn Gabe and Lily Ray have both publicly flagged this patent as deeply concerning for publishers. It’s the technical scaffolding for a world where Google’s agents don’t just cite your content, but replace your destination.
Meanwhile, the opt-out mechanisms available to publishers remain limited. Google-Extended, the robots.txt token for controlling Google’s AI systems, explicitly does not prevent content from being used in AI Overviews or AI Mode. It only controls whether content is used for training Gemini models. As of April 2026, there is no publisher opt-out from AI search features. Google has acknowledged this gap and described building one as a “huge engineering project,” but no timeline has been committed.
The regulatory landscape offers the only credible forcing function for rebalancing. The UK CMA designated Google with Strategic Market Status on October 10, 2025, explicitly including AI Overviews and AI Mode within its scope. The CMA’s January 28, 2026, Conduct Requirements proposed that publishers should be able to opt out of AI training without incurring a Search ranking penalty, but final rules haven’t landed yet. In the EU, Digital Markets Act compliance creates additional constraints on how Google can bundle AI features with Search. And the NYT v. OpenAI case continues to reshape the legal landscape: a January 5, 2026, court order forcing production of 20 million anonymized ChatGPT logs materially shifted fair-use risk calculations and is likely to drive licensing waterfalls across the industry through the rest of 2026.
The honest reading of all of this is uncomfortable but necessary. Google’s monetization is decoupling from the open web. Ad revenue grows because AI features drive more queries and more engagement within Google’s surfaces, and not because more users are clicking through to publishers. The licensing deals Google has signed with AP, Financial Times, Der Spiegel, El País, and others are extensions of existing News Showcase agreements, not standalone AI compensation programs. For the vast majority of publishers and businesses, the value exchange is becoming structurally one-directional: Google ingests your content, synthesizes it for users, and keeps them on its surfaces while the ad revenue accrues to Google.
Pichai’s 72-minute silence on this topic wasn’t an omission. It was a position.
What you should actually do: strategic imperatives for 2026
Everything up to this point has been diagnosis. Here’s where it becomes operational.

The shift from “optimize for rank” to “be selectable by agents” isn’t a slogan, but a practical reorientation that touches content architecture, technical infrastructure, measurement, budget allocation, and organizational priorities. Not everything needs to change overnight, but the direction needs to be set now. Pichai named 2027 as the inflection. The preparation window is 2026.
First: pivot from page-level ranking to passage-level retrievability. When AI Mode decomposes a query into 8 to 12 sub-queries, it retrieves passage-level answers, not pages. A single well-structured page can be cited across multiple sub-queries if each major section answers a distinct probable fan-out question. The practical implication is that every H2 on a priority page should function as a standalone, declarative answer to a plausible sub-query.
Structure matters at the sentence level, too. Kevin Indig’s analysis of 1.2 million ChatGPT citations found that 44.2% of citations come from the first 30% of a page, and that a declarative opening — a clear “X is Y” statement — lifts citation rates meaningfully. Pair claims with specific numbers and a publication date. That combination is the strongest citation signal available across current AI retrieval systems.
There’s a critical measurement gap here: approximately 95% of fan-out sub-queries have zero traditional search volume. They don’t appear in Search Console. They don’t show up in keyword research tools. You won’t find them by looking at the data you’re used to looking at. Tools like iPullRank’s Qforia or Mark-Williams Cook’s Queryfan.com, and similar fan-out simulation platforms are becoming necessary to surface the sub-query sets that AI Mode actually generates for your priority topics.
Second: dominate the entity landscape of your ontology along the entire search and customer journey.
My recommendation is to experiment with and adapt my 8-task workflow for engineering high-performance content hubs.
Third: build and defend your entity’s presence. In a world where agents pick one answer, one merchant, one source — not ten — entity disambiguation is the gatekeeper. If your brand isn’t a resolved entity in Google’s Knowledge Graph, you don’t enter the candidate pool for fan-out retrieval. It’s that binary.
The canonical About page with Organization or Person schema, sameAs links to Wikidata, LinkedIn, Crunchbase, and your Knowledge Panel, is the strategic anchor. Jason Barnard’s Understandability–Credibility–Deliverability framework remains the clearest operating model for this work: make sure Google understands what your entity is, finds it credible through corroborating sources, and can deliver your content in the right context. Author-entity optimization is no longer optional — it’s a prerequisite for passage-level credibility in AI retrieval systems.
I wrote more extensively about “Branded SEO” in this guide published on Advanced Web Ranking.
Fourth: reallocate 30 to 40% of your content budget off-domain. This is where many SEO strategies are still underweight. Data from Stacker indicates that 85% of AI citations come from third-party pages, not brand-owned content. LinkedIn has become one of the most-cited domains on ChatGPT, with a majority of those citations coming from individual creator posts rather than company pages. Reddit, YouTube, Quora, G2, and Trustpilot are now authority surfaces that AI systems draw from heavily.
Earned digital PR, expert bylines on industry publications, podcast appearances that get transcribed and indexed, detailed LinkedIn analysis posts… these are no longer “nice to have” brand-building activities. They’re the corroboration layer that passage ranking uses to assess source credibility. The old rule — “don’t build on rented land” — needs updating. In an environment where the click itself is disappearing, optimizing for influence and citation frequency across platforms matters more than concentrating all content on your own domain.
Fifth: engineer for agent access as a C-suite infrastructure priority. This is no longer a technical SEO task list, but an infrastructure decision that needs executive sponsorship.
This means:
- Unblock AI crawlers at the CDN layer, not just in robots.txt.
- Serve critical content in raw HTML because AI crawlers other than Googlebot generally do not render JavaScript.
- For e-commerce specifically: implement /.well-known/ucp endpoints.
- Enrich Merchant Center feeds with the expanded attribute set from NRF 2026 (Q&A, compatible accessories, substitutes).
- Ensure sub-second server response times. Agents time out. They don’t retry the way a human would.
Monitor Google-Agent activity in your server logs, because no trace of it will appear elsewhere. Instrument Cloudflare logs or Microsoft Clarity’s Bot Activity report (launched February 2026) to track AI request volume as a dashboard metric. And begin evaluating WebMCP implementation for your transactional pages. It’s early — Chrome Canary only, behind a flag — but the sites that are agent-ready when the standard goes mainstream will have a structural advantage over those scrambling to implement it later.
Sixth: design for Decision Compression. This concept captures something important about how the buying journey is changing in agentic Search. The path from discovery to purchase, which used to span multiple searches, multiple tabs, and multiple site visits, is collapsing into a single AI-mediated interaction. The agent researches, compares, and executes, and the user approves or rejects the result.
For businesses, this means simplifying product portfolios so agents can categorize and compare your offerings cleanly. It means clarifying value propositions in structured, machine-readable formats, not just in marketing copy designed for human persuasion. It means ensuring that product data feeds are complete, accurate, and optimized for AI curation, because an agent evaluating your product against a competitor’s will make its assessment based on structured attributes, not on how compelling your landing page headline is. UCP adoption is becoming a strategic necessity for any e-commerce business that wants to remain transactable within AI surfaces.
Seventh: complement rank-tracking with a blended visibility and influence KPI stack. The dashboards most teams still use measure a funnel that no longer captures the majority of Search interactions. When 93% of AI Mode sessions end without a click, tracking rank positions and CTR for informational queries is measuring an increasingly small slice of total visibility.
Build a monitoring layer using tools designed for AI citation tracking — WaiKay.io for Brand & Brand per Topic visibility, Profound or Scrunch AI for enterprise, Peec AI, Otterly, and Advanced Web Ranking for mid-market, Ahrefs Brand Radar or Semrush AI Visibility Toolkit as add-ons to existing platforms.
Use brand-frequency methodology: run 60 to 90 prompt variations per priority query across multiple AI systems, because individual responses are non-deterministic. No single query will give you a reliable picture.
Track AI Request Share and AI Conversion Rate as dashboard KPIs alongside traditional traffic metrics. And for informational queries specifically, consider retiring pure-CTR OKRs entirely, because they measure a funnel that no longer exists for that intent type.
Eighth: brand is the moat, hence fund it accordingly. This is the imperative that sits above all the tactical ones, and it’s the one most likely to meet internal resistance because it’s harder to measure in the short term.
When Pichai’s “agent manager” executes a UCP checkout or a Mariner booking, the agent picks one answer, one merchant, one source.
Long-tail hedging — the strategy of publishing enough content to rank for hundreds of variations and capturing traffic across the tail — loses its leverage in this environment. What works instead is category-leader positioning on the defining question of your space, original data and research that AI systems want to cite, consistent cross-platform brand-entity coherence, and sustained brand-recognition investment.
There’s quantitative evidence for this already. Another Kevin Indig’s analysis suggests that a meaningful percentage of AI Mode users override the AI’s top suggestion when they recognize a brand lower in the response. Brand recognition acts as a trust signal that competes with — and sometimes overrides — the AI’s own ranking logic. For 2026, the brand budget should meet or exceed the content budget. That’s a significant reallocation for most organizations, but the structural logic supports it.
A plausible calendar, and what to expect through 2027
Timelines in this industry age poorly. But Pichai was unusually specific in the interview about when he expects certain shifts to happen, and Google’s publicly committed launches and patent filing cadences provide enough triangulation points to build a reasonable forward view. What follows is necessarily hypothetical, but grounded in what’s already been announced, what’s already shipping, and what the infrastructure constraints allow.
May 2026 is the next major inflection point, because Google I/O falls on May 19–20. Based on the product cadence of the last twelve months, expect:
- A preview of Gemini 3.5 or Gemini 4.
- An expansion of AI Mode’s agent surfaces beyond tickets and reservations.
- Likely a second version of the Universal Commerce Protocol with expanded payment partner support.
- Chrome auto-browse expansion into the EU is plausible but contingent on Google’s Digital Markets Act posture; the regulatory environment will determine how aggressively agentic features can be deployed in European markets.
- Android XR glasses with Samsung, which Google has been telegraphing since late 2025, may get a consumer SKU announcement here.
Through the summer and into the second half of 2026, we may expect these things:
- The pattern from Google I/O 2025 should repeat: capabilities that debut in AI Mode will graduate into core Search as they prove stable. Google said explicitly at I/O 2025 that AI Mode is where frontier Gemini capabilities arrive first, and with feedback, many move into the standard Search experience.
- The Google Docs and Workspace “sharp improvements” Pichai committed to in the interview should materialize in this window.
- Agent Mode in the Gemini app, currently limited to AI Ultra subscribers, is likely to expand to broader tiers.
- The unreleased post-training technique Pichai hinted at — “I don’t want to be specific about the second one, but we’ll publish it one day” — may surface as a Gemini 3.5 or 4 quality jump.
Q3 and Q4 2026 will likely be shaped by two forces: the expansion of agentic commerce and the regulatory fallout from major AI litigation.
On the commerce side:
- Agentic checkout via UCP should open to broader user tiers beyond the current AI Pro/Ultra gating.
- Project Mariner and Chrome auto-browse are likely to expand beyond US-only access, initially with limited daily actions for free-tier users.
- The agentic commerce layer — which today operates in narrow verticals like tickets, restaurants, and appointments — should become a more transversal infrastructure across Search and Gemini.
On the regulatory side:
- The NYT v. OpenAI discovery process will produce its most consequential outputs in this window. The January 2026 court order requiring production of 20 million anonymized ChatGPT logs materially shifted the fair-use risk calculus for the entire industry. Whatever emerges from that discovery will drive licensing waterfalls, and not just for OpenAI, but for every company ingesting publisher content for AI synthesis. Google may respond with an expanded publisher licensing program extending beyond its current News Showcase participants.
- The UK CMA’s final Conduct Requirements for AI in Search are also expected to land in 2026, and could include a meaningful publisher opt-out mechanism (or could disappoint.)
Google’s typical year-end core algorithm update — likely December 2026 — will be worth watching closely. If it follows the trajectory of the March 2026 update, expect continued demotion of scaled AI-generated content and aggregator sites, with deeper preference for destination brands and institutional sources. The algorithmic direction and the product direction are converging: both reward entities with demonstrated expertise, original data, and cross-platform corroboration.
2027 is when Pichai expects the structural shift to become undeniable. His exact framing: “I definitely expect in some of these areas, ’27, to be an important inflection point. I expect ’27 to be a big year in which some of those shifts happen pretty profoundly.” The binding constraints he named — identity and access controls, permissions architecture, change management, organizational role redesign — are what he expects to be solved by then. Once they are, consumer agents with persistent, long-running tasks become viable at mass-market scale, not just for paying subscribers.
The capital infrastructure supports this timeline. Memory supply constraints should ease modestly as new fabrication capacity comes online. TurboQuant-class compression reduces the per-query compute cost of agentic features. Flash-tier model distillation continues to close the gap between Pro and Flash capability at dramatically lower serving cost. The combination makes it economically viable to extend agentic Search to free-tier users at scale — which is exactly what Pichai’s “99.9% of the world isn’t living this future yet” statement was setting up.
Two risks could delay this calendar:
- Pichai’s own security shock. If AI agents break critical software infrastructure in a visible, public way — the “sharp moment” he described — the resulting regulatory and public-trust backlash could force a retrenchment that slows deployment by 12 to 18 months. The DeepMind Agent Traps research suggests this isn’t improbable.
- A memory-supply collapse more severe than currently projected, which could force Google to ration agentic features to paying tiers for longer than planned, fragmenting the market between users who have agent access and those who don’t.
Neither risk changes the direction. Both could change the speed.
Conclusion: three shifts that demand strategic action now
The most strategically honest reading of Pichai’s interview is this: Google is no longer building Search for humans to click through. It is building a system where humans delegate, agents execute, and the information and transaction layers are mediated end-to-end by Google’s surfaces. That is the future being declared – in my honest opinion – not as a possibility, but as a plan backed by the largest infrastructure investment in the history of the technology industry.
Cross-referencing Pichai’s statements with Google’s actual shipping behavior, patent filings, earnings data, and product documentation confirms three structural shifts that should reorder how senior SEOs, growth leaders, and business owners think about their relationship with Search.
The optimization target has moved from documents to passages to agent-selected answers. Document-level ranking still matters for classic Search remnants and for agents assessing source credibility. But passage-level retrievability and declarative answer structure now determine AIO/Mode citation. Fan-out simulation and passage engineering are baseline operations, not advanced tactics. Continuing to measure success exclusively through SERP rank positions and click-through rates is measuring a funnel that handles a shrinking share of total Search interactions.
The economic relationship between Google and publishers has become extractive by design, not by accident. Pichai’s silence on publisher economics, combined with Google’s accelerating ad revenue during publisher CTR collapse, the Google-Extended opt-out gap, the AI-synthesized landing page patent, and UCP’s merchant intermediation, describes a coherent strategy. Google is capturing the transaction layer while outsourcing content risk to the open web. Regulatory action — UK CMA, EU DMA, NYT v. OpenAI — remains the only credible forcing function for rebalancing. Plan accordingly.
The window to build agent-ready commerce and brand infrastructure is 12 to 18 months. Pichai named 2027 as the inflection point. The zero-sum agent selection moment — when one merchant wins the booking, not ten — rewards category-leader brands, comprehensive entity corroboration, UCP-ready infrastructure, and original data. Organizations executing on these fronts in 2026 will own the equilibrium position by the time mass-market agentic Search lands. Those still optimizing exclusively for ten blue links won’t just lose traffic, they’ll lose the ability to be selected at all.
We’ve been through Panda, Penguin, mobile-first, BERT, and the AI Overview anxiety of 2025. Each time, the profession adapted because the people doing this work are, fundamentally, problem solvers. This time, the adaptation is structural rather than tactical. The tools change, the measurement changes, the budget allocation changes, and the very definition of what “visibility” means in Search is being rewritten.
But the core skill — understanding what systems value and building for it — remains exactly the same. The systems have just gotten considerably more ambitious about what they’re trying to do. So should we.
